因為專業
所以領先
![[LOGO]](/template/default/image/logob.png)
![[LOGO]](/template/default/image/logoll.png)
因為專業
所以領先

我們說AI芯片,一般是泛指所有用來加速AI應用,特別是基于神經網絡的深度學習應用的硬件,它可以是一顆獨立的芯片,也可以是芯片中的模塊,其基本技術都是相關的。

綜合來說,AI計算的需求爆炸性增長,而通用處理的處理能力很難提升,這中間就出現一個很明顯的gap。所以,一個很直接的想法就是,如果通用處理器不能滿足AI計算的需求,我們是否可以設計針對AI計算的專用處理器呢?答案當然是肯定的。這也就是領域專用計算的概念。
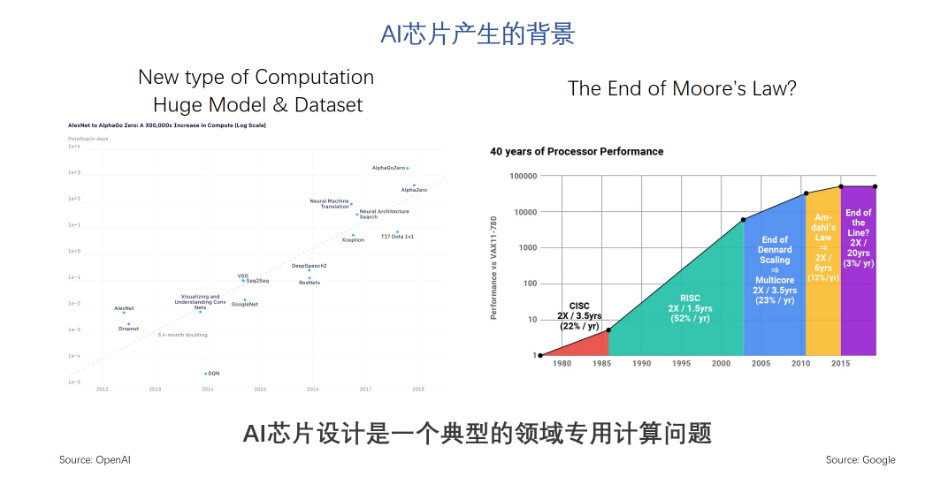
一般來說,一個領域是不是適合開發專用的處理器有兩個條件,第一是這個領域的應用需求足夠大,有很強的動力驅動相應的研發投入;第二是這個領域的計算模式限定在一個較小的集合,這樣我們才有可能用專用硬件來對這些特定的運算進行加速。AI領域正好滿足這兩個條件。因此,我們說AI芯片設計是一個典型的領域專用計算問題,也就是domain specific computing。
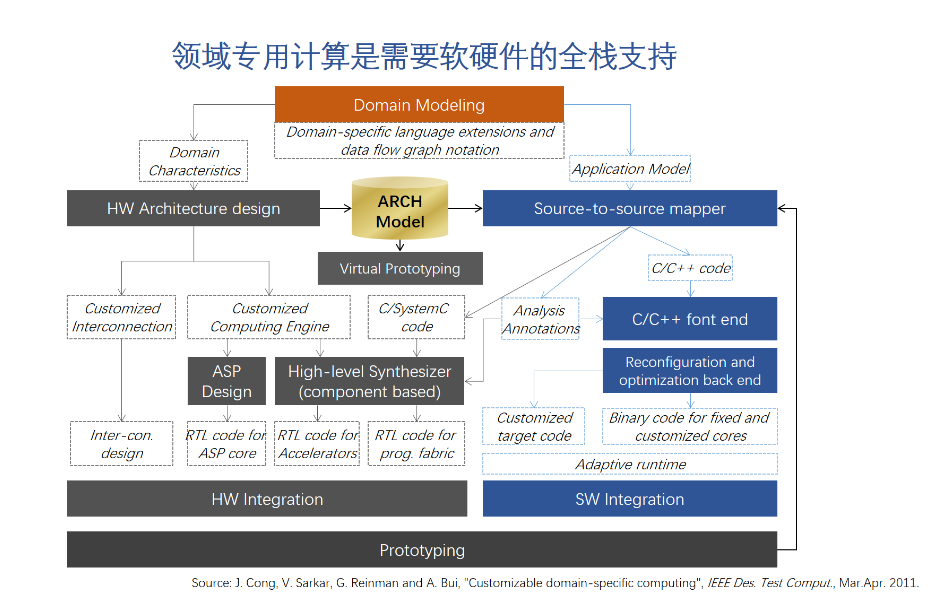
圖的右半部分就是軟件開發的工作和相應的工具。細節內容我就不展開講了,感興趣的朋友可以看看我的公眾號上關于專用處理器的文章。這里我只想強調一點,就是我們設計一個專用處理器,往往需要設計新的指令集架構,編程模型,甚至是新的編程語言。這也意味著我們可能沒有現成的軟件工具可以使用,我們在設計和優化新的硬件的同時,必須打造新的軟件工具鏈。只有提供全棧的軟硬件,才能讓用戶特別是開發者利用好新硬件的能力。這個也是專用處理器設計的一個巨大挑戰。
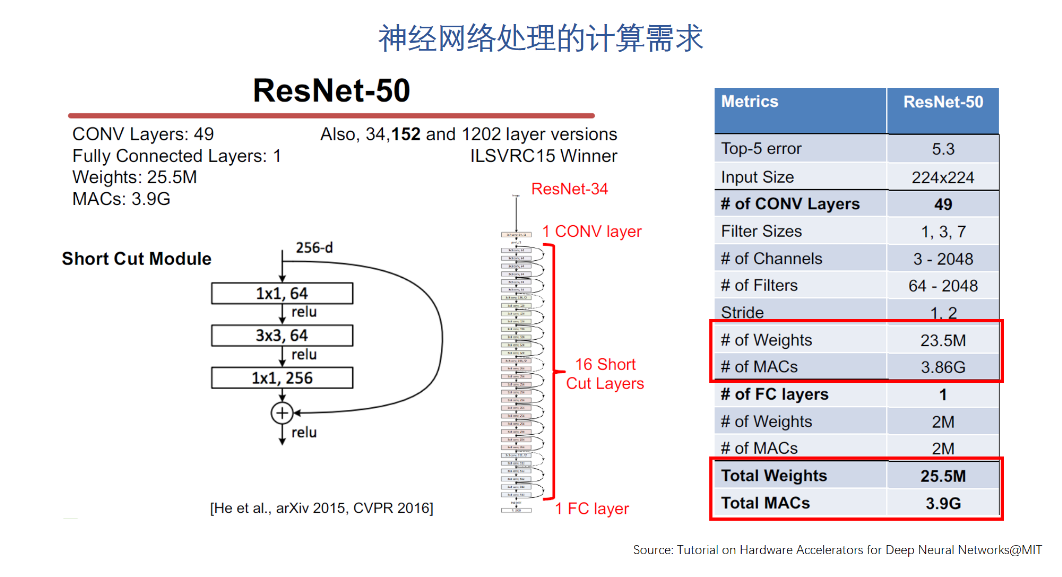
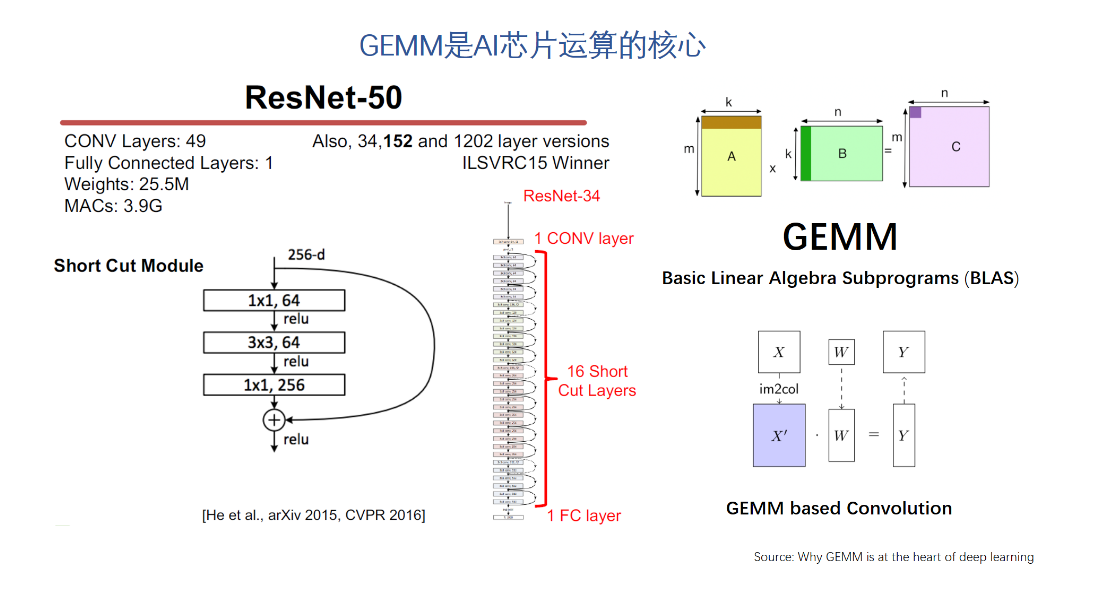
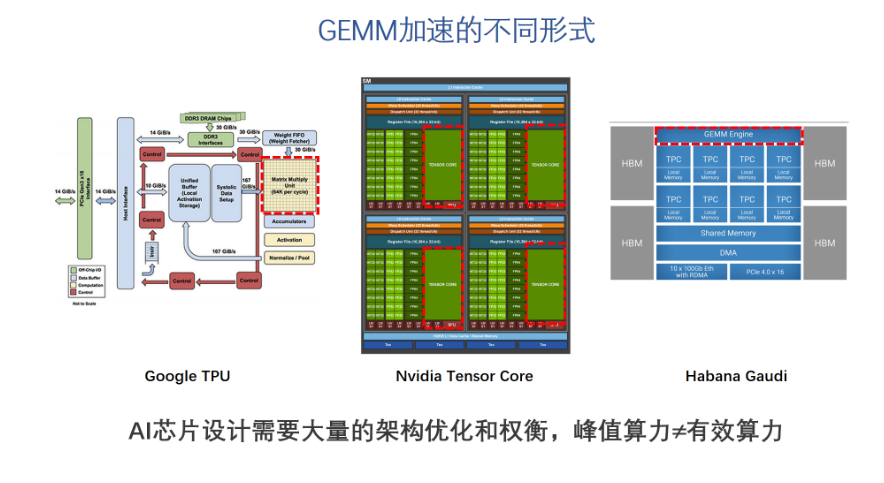
對GEMM的加速效果是受很多因素影響的。首先要有大量的運算單元,這個相對比較容易,但即使有了大量的運算單元,如果數據不能有效的供給到GEMM引擎,則它理論上計算能力再強也發揮不出來。這也是為什么我們經常看到AI芯片宣傳的峰值運算能力很強,但跑實際網絡的有效算力就差了很多。此外,還有很多需要做架構優化和權衡的問題。比如可編程性。值得一提的是,一直強調自己是從做硬件之前就開始做軟件工具的。從實際展示的結果來看,芯片利用率還是比較高的,這個應該是硬件架構比較平衡,軟件工具比較完善才可能做到的。
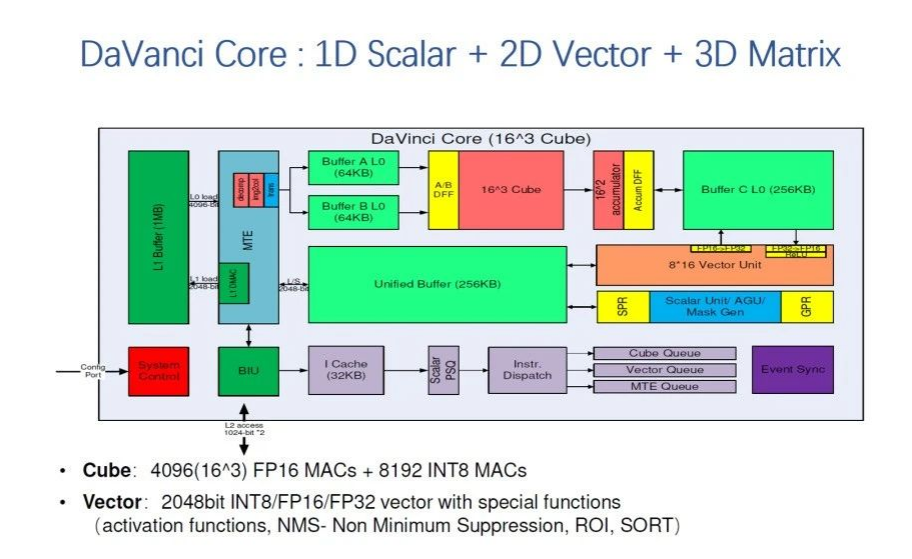
下面我們看一下展示的達芬奇AI處理器架構,它吸取了過去幾年AI硬件加速的經驗,融合向量,標量和矩陣的的運算。3D Cube:16*16*16三維彈性立方體,可在一個時鐘周期內完成4096個FP16 MAC運算。而這個核通過不同的配置,可以作為 幾十毫瓦的IP到支持幾百瓦的芯片,的不同場景,比如高能效的Ascend 310到算力最強的Ascend 910。

當然,這幾年AI芯片的熱潮也給我們帶來一些很有意思的,比較特殊的架構。比如,Grophcore的IPU是一個大規模并行,同構眾核架構。最基本的硬件處理單元是IPU-Core,它是一個SMT多線程處理器,可以同時跑6個線程,更接近多線程CPU。芯片上有一千多個小的這種通用處理器核。同時,芯片沒有外部存儲,而是實現了300M左右的片上存儲,這個也是很少見的。

如果總結一下這幾年AI計算加速在產業的發展,簡單來說就是無芯片不AI。從云到邊到端的各種場景都需要AI運算能力,因此也都需要AI加速。但是在不同的場景下,對AI加速的需求又有很大差別。
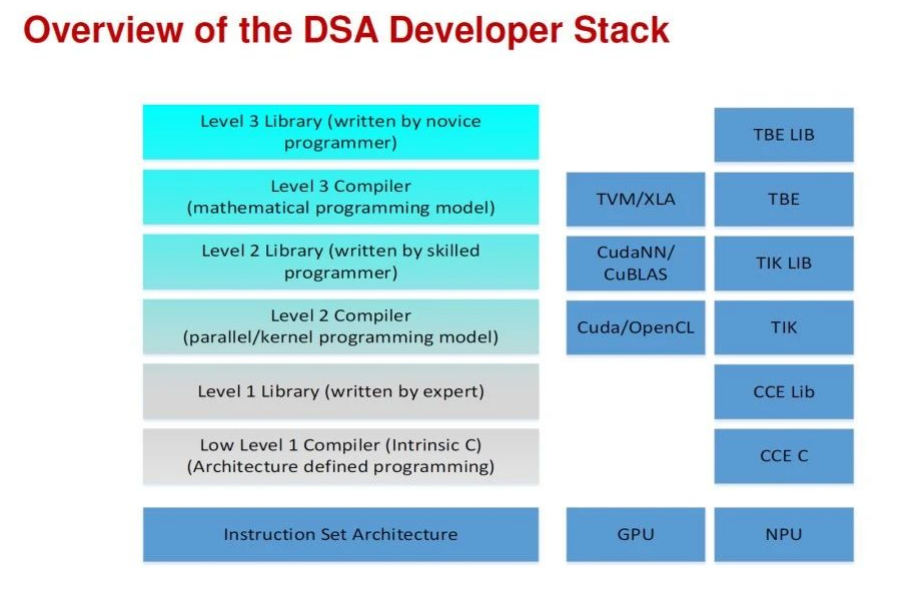
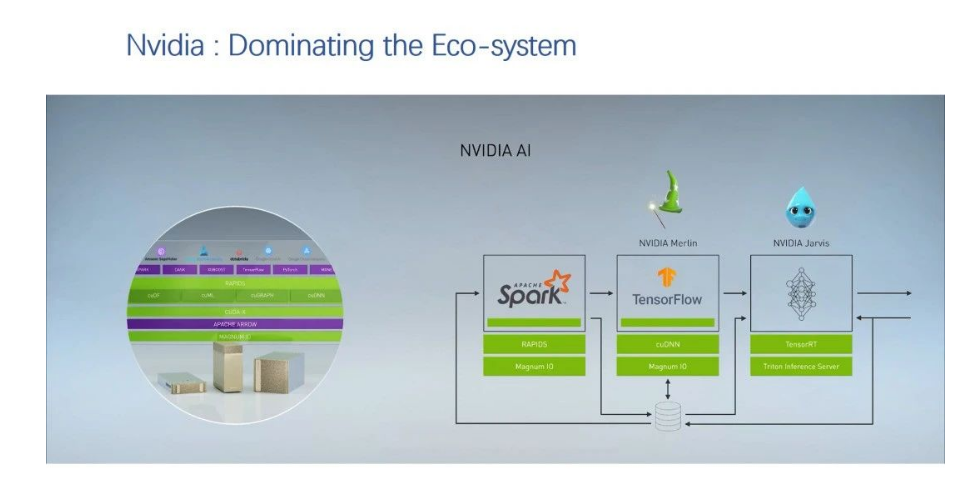
這個例子里面中間一列,我們看到目前業界應用最多的軟件棧。硬件基于Nvidia GPU,軟件是基于CUDA。正好Nvidia剛剛發布了新的AI軟硬件產品,我們不妨展開來看一下。

A100是7nm工藝,使用HBM2存儲器接口,3D封裝,整體性能有大幅提升。具體來說,Tensor Core支持更多的數據類型,特別是AI中常用的數據類型,支持固定結構的2:4稀疏化處理。FP16/BF16的峰值處理能力是312TFLOPS,INT8的峰值處理能力是624TOPS,如果是稀疏處理的情況,則最高性能翻倍。近幾年很多AI芯片初創公司都說自己的芯片硬件性能比Nvidia GPU高幾倍,不過現在看來,即使單看硬件,A100的指標也是最強的。

在A100的基礎上,整個硬件產品線也做了升級,從顯卡到云服務器到邊緣服務器到自動駕駛和智能機器平臺,非常完整。
芯片封裝清洗:
合明科技研發的水基清洗劑配合合適的清洗工藝能為芯片封裝前提供潔凈的界面條件。
水基清洗的工藝和設備配置選擇對清洗精密器件尤其重要,一旦選定,就會作為一個長期的使用和運行方式。水基清洗劑必須滿足清洗、漂洗、干燥的全工藝流程。
污染物有多種,可歸納為離子型和非離子型兩大類。離子型污染物接觸到環境中的濕氣,通電后發生電化學遷移,形成樹枝狀結構體,造成低電阻通路,破壞了電路板功能。非離子型污染物可穿透PC B 的絕緣層,在PCB板表層下生長枝晶。除了離子型和非離子型污染物,還有粒狀污染物,例如焊料球、焊料槽內的浮點、灰塵、塵埃等,這些污染物會導致焊點質量降低、焊接時焊點拉尖、產生氣孔、短路等等多種不良現象。
這么多污染物,到底哪些才是最備受關注的呢?助焊劑或錫膏普遍應用于回流焊和波峰焊工藝中,它們主要由溶劑、潤濕劑、樹脂、緩蝕劑和活化劑等多種成分,焊后必然存在熱改性生成物,這些物質在所有污染物中的占據主導,從產品失效情況來而言,焊后殘余物是影響產品質量最主要的影響因素,離子型殘留物易引起電遷移使絕緣電阻下降,松香樹脂殘留物易吸附灰塵或雜質引發接觸電阻增大,嚴重者導致開路失效,因此焊后必須進行嚴格的清洗,才能保障電路板的質量。
合明科技運用自身原創的產品技術,滿足芯片封裝工藝制程清洗的高難度技術要求,打破國外廠商在行業中的壟斷地位,為芯片封裝材料全面國產自主提供強有力的支持。
推薦使用合明科技水基清洗劑產品。
上一篇:半導體行業超純水水質標準





![[x]](/template/default/picture/closeimgfz1.svg)





![[x]](/template/default/picture/closeicon1.png)

![[→]](/template/default/picture/you.svg)









![[↓]](/template/default/image/xiangxiaimgfaz1-1.svg)




![[→]](/template/default/image/zixuniconim1.png)
![[x]](/template/default/image/closeicon1.png)

![[圖標]](/template/default/picture/fc1c83eb02c951ce168aaebde4fd8205.svg)



![[↑]](/template/default/picture/rtxiangshangimg1.svg)